
Claude Opus 4.7 Is Out. Here’s What I Actually Think.
And a harder question about where AI-driven engineering is really going.
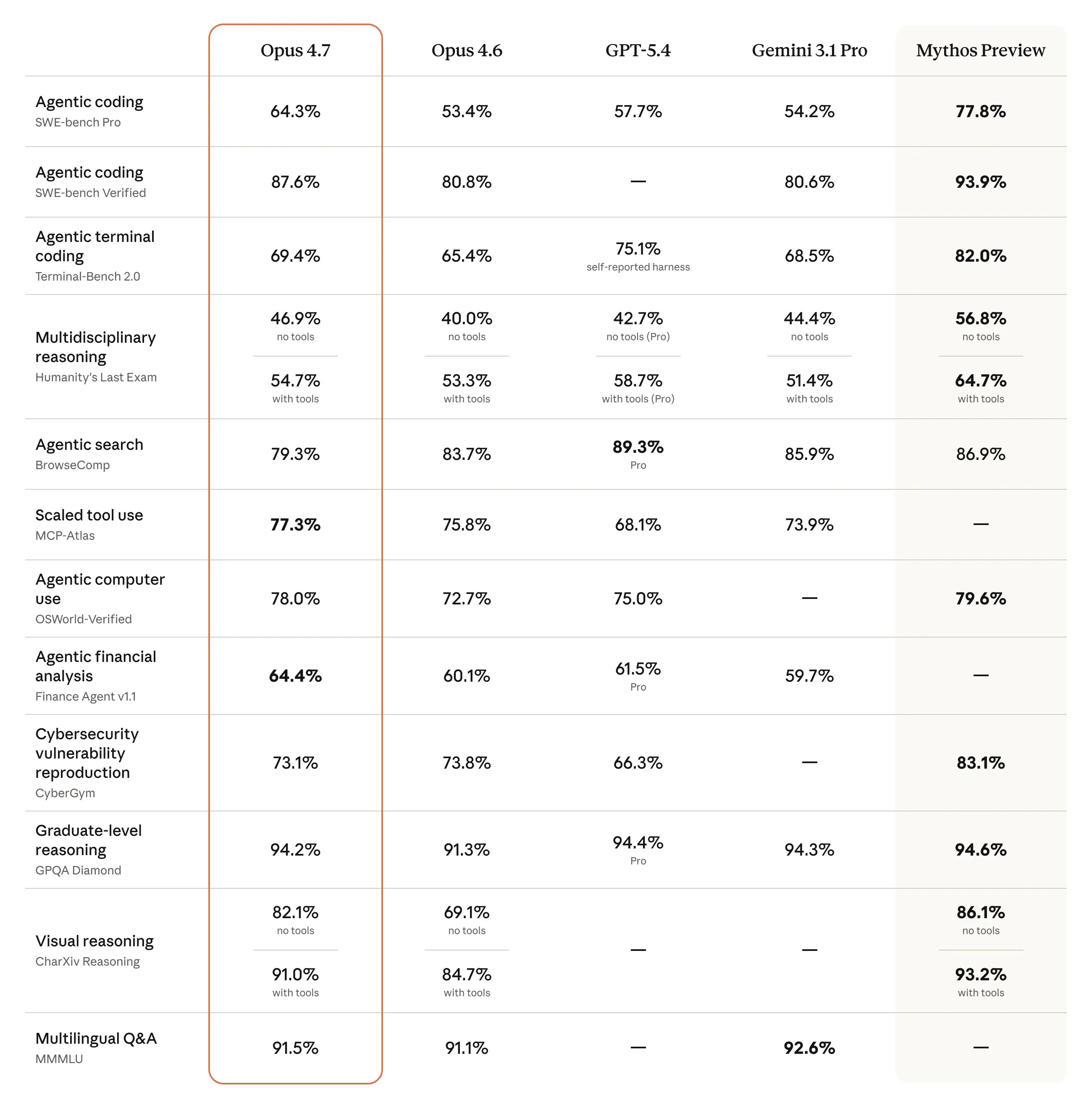
Anthropic released Claude Opus 4.7 this week. The benchmarks look strong — better coding performance, dramatically improved vision, more reliable long-running tasks, and a model that now verifies its own outputs before reporting back. On paper, it’s a meaningful upgrade.
But here’s my honest reaction: I’m cautiously interested, not excited.
Let me explain why — and what it reveals about a bigger question in AI-driven software engineering.
The Way I Actually Use Opus
If you’ve read my work before, you know I build AI-driven software engineering workflows. And in that context, I’ve landed on a pattern that works well for me:
Opus handles the thinking. Sonnet handles the doing.
When I’m starting a new feature, I bring Opus in for the hard stuff — brainstorming approaches, stress-testing assumptions, defining the architecture. This is where raw reasoning quality matters most. A bad plan executed perfectly is still a bad outcome, and Opus is genuinely better at catching the flaws before a line of code is written.
Then I hand off to Sonnet for code generation and execution. It’s faster, cheaper, and more than capable of implementing a well-defined plan. The combination works well precisely because each model is doing what it’s best at.
This isn’t just a cost hack. It’s a philosophy: AI models, like human team members, should be deployed where their specific strengths create the most leverage.
So Why Am I Not Just Upgrading?
Because Opus 4.7 uses more tokens than Opus 4.6.
Anthropic is transparent about this — the new tokenizer and increased reasoning at higher effort levels mean the same input can map to roughly 1.0–1.35× more tokens. Their internal evals suggest the net efficiency is still favourable. Maybe it is. But “maybe” isn’t good enough when you’re running Opus on your most expensive, most critical tasks.
Opus has always required intentionality. You can’t just point it at everything and hope for the best — you’ll exhaust your token budget fast. The whole reason my Opus-Sonnet workflow exists is because I learned that lesson the hard way. If 4.7 compounds that constraint without delivering a proportional improvement in output quality, the calculus doesn’t change — it gets worse.
To be clear: I haven’t tested it enough yet to make a final call. And some of what I’m reading from early testers — particularly around long-horizon agentic tasks and self-verification — is genuinely compelling. But I’d encourage anyone evaluating this upgrade to resist the benchmark hype and measure what matters to them: cost per useful outcome, not raw capability scores.
The Bigger Picture I’m Watching
Opus 4.7 is one release. The more interesting question it surfaces is: where is all of this actually going?
Here’s what I think: the next frontier in AI-driven software engineering isn’t more powerful individual models — it’s smarter orchestration between them.
We’re moving from “which model should I use?” to “how do I build a system where the right model handles the right task, automatically?” The teams winning at this right now aren’t the ones with the biggest models — they’re the ones with the best routing logic, the best context management, and the clearest understanding of where AI adds leverage versus where it burns budget.
Opus 4.7’s new xhigh effort level and task budgets (now in public beta) are a step in that direction — giving developers more control over how much the model reasons on hard problems. That kind of fine-grained control is going to matter a lot as workflows get more complex.
The models will keep improving. That’s almost guaranteed. The question is whether your workflows are built to take advantage of that — or whether you’re still treating AI as a single, monolithic tool you point at problems and hope for the best.
What I’ll Be Watching
Over the next few weeks I’ll be running Opus 4.7 on my actual planning and architecture tasks — the ones where Opus earns its keep. I’ll share what I find.
If you’re doing similar things, I’d genuinely love to hear how you’re approaching the cost-quality tradeoff. Hit reply and let me know.
Until next time.