
Caching, but without ElastiCache - Saving $39/month
How I saved roughly $39 a month by substituting Elasticache with Supabase
As most of us can agree, caching is one of the most important pieces of any software development, because of benefits including, but not limited to, less pressure on database and quick read (and in some cases write) times.
While this is true, it also requires to build and maintain the infrastructure around it, which not only adds the costs for the server, but also managing it (specially if you self-host it). Even if you don’t self host it and use a product like AWS Elasticache, the cost can be a burden, specially when you are bootstrapping everything and just starting out, where every penny matters.
I found myself in the same situation when I was working on a side project and I had to use a cache, but I didn’t want to pay for a server or ElastiCache.
I was already using Supabase Cloud’s free version for this project, so I thought of using Supabase only for this purpose. If you have used Supabase before, you’d know that the free limits apply to an organisation and not the account. This meant that I could create a new organisation and maintain upto 500MBs of cache for free in Supabase cloud itself.
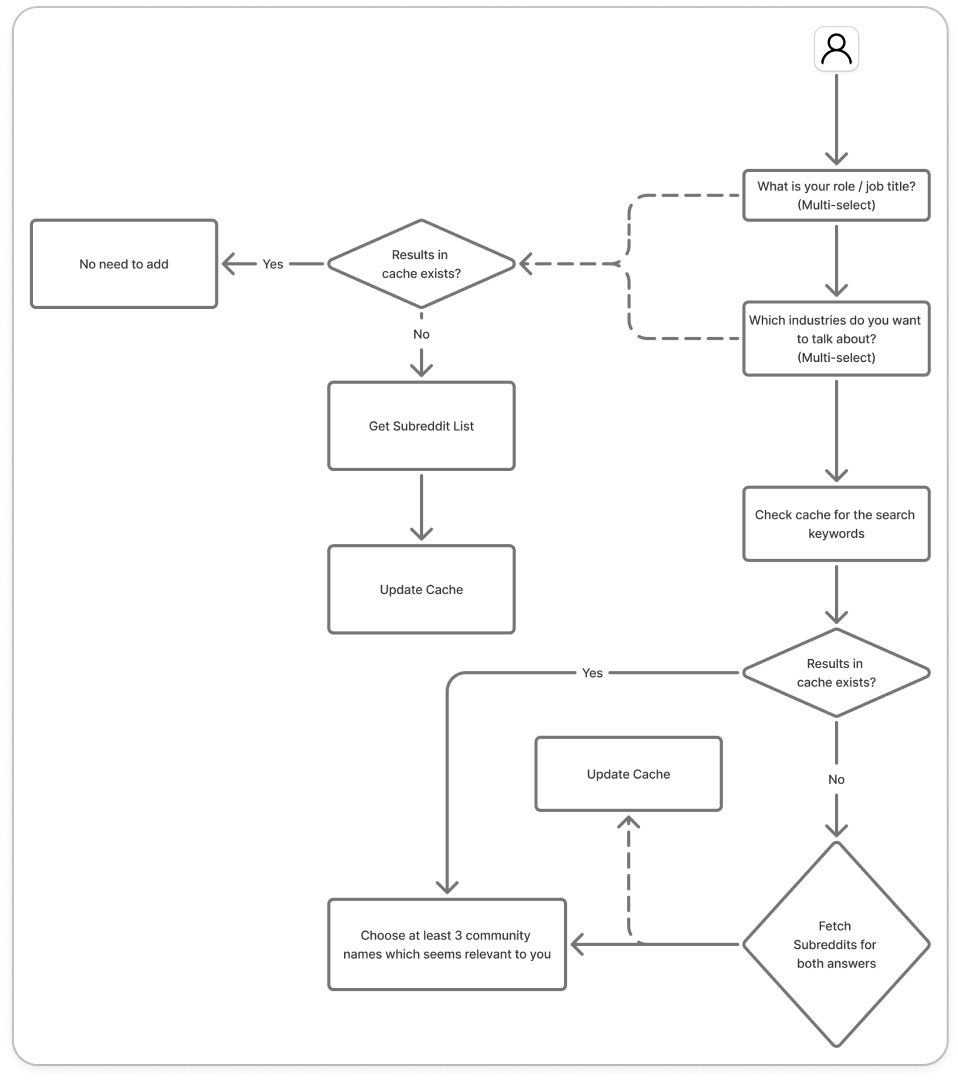
Let’s understand the main problem statement - I am using the external API for Reddit to fetch the list of subreddit names from a given keyword. The issue is that this API takes roughly 3-4 seconds for the results, and I don’t want my users to wait for that long, specially for each unique request.
Assumption: Assuming that the subreddit list wouldn’t change or have a significant difference at least for a week, I can cache the results for keywords the users have already searched for, for 1 week.
So here’s how I handled it - for every unique request, I follow this approach:
I maintain a config table in the main database, which stores the location, schema name and expiry of that cache schema.
If the config entry doesn’t exist, it means the cache schema also doesn’t exist, so I create a new schema with a predefined name and add entry to config table with expiry of T+7 Days.
If the config entry exists, then I need to check if it’s expiring today. If it’s expiring, then the cache schema needs to be destroyed and recreated again.
As a part of the schema creation or replacement, I also create a predefined set of tables which will act as my cache tables.
I then query the “subreddit_list” table in the cache schema for the keyword given by the user.
If EXISTS, then I simply return the entries from the cache
If DOES NOT EXIST, then I query the reddit API, get results and save it in the cache.
Here’s a visual representation of how it looks (the dotted lines mean they run as non-blocking background tasks):
Now, everything runs on AWS Lambda and I use Supabase to manage my databases and saving the money I would have had to spend on AWS Elasticache for cache.
Would be happy to hear your thoughts on this! I am open to hearing better alternatives to this approach, if any.